인덱스란?
- 어떤 데이터가 디스크의 어느 위치에 있는지에 대한 정보를 가진 주소록과 같음
- 데이터 - ROWID(주소) 쌍으로 저장됨
- 일반적인 select 쿼리 실행 시 먼저 메모리의 database buffer cache를 체크
- buffer cache에는 자주 사용되는 테이블들이 캐싱되어 있어 여기에 데이터가 있을 경우 바로 찾아 출력하고 없을 경우 하드디스크에 있는 데이터 파일에서 데이터를 찾음
- 인덱스를 사용하면 이런 과정을 거치지 않고 바로 주소를 통해 찾아감
인덱스 생성 원리?
- 해당 테이블을 모두 읽고 인덱스를 만드는 동안 데이터가 변경되면 문제가 되므로 해당 데이터들이 변경되지 못하도록 조치한 후 메모리(PGA의 Sort Area)에서 정렬
- 전체 테이블 스캔 → 정력 → Block 기록 (PGA내의 Sort Area 공간 부족시 Temporary Tablespace이용해 정렬)
인덱스 동작원리?
- 데이터 파일의 블록이 10만개가 있다고 가정할때 select문 실행시
- 1) server process가 구문분석과정을 마친후 database buffer cache에 조건에 부합하는 데이터가 있는지 확인
- 2) 해당 정보가 buffer cache에 없다면 디스크 파일에서 조건에 부합하는 블럭을 찾아 database buffer cache에 가져온 뒤 사용자에게 보여줌
- 이 경우 index가 없으면 10만개 전부 database buffer cache로 복사한뒤 풀스캔으로 찾게됨
- index가 있으면 where절의 조건의 컬럼이 index의 키로 생성되어있는지 확인한 뒤, 인덱스에 먼저 가서 조건에 부합하는 정보가 어떤 ROWID를 가지고 있는지 확인 후 ROWID에 있는 블럭을 찾아가 해당 블럭만 buffer cache에 복사
인덱스 사용이 불가능한 경우?
- 인덱스 컬럼을 조건절에서 가공하면 인덱스 사용이 불가능
- 부정형 비교는 인덱스 사용 불가능
- is null 조건만으로는 인덱스 사용 불가
인덱스 종류
1. B-TREE 인덱스
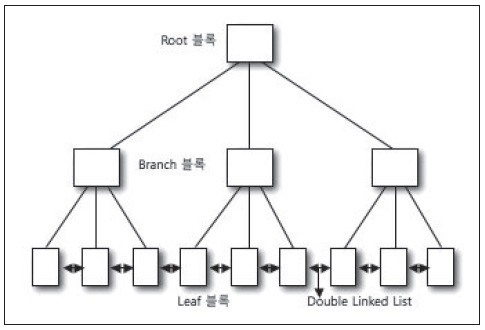
- 루트 블록(ROOT BLOCK) : 분기 값 저장, 인덱스의 다음 단계의 브랜치 블록을 가리키는 항목 포함
- 브랜치 블록(BRANCH BLOCK) : 분기 값 저장, <Separator Key, DBA>로 구성, 밑의 리프 블록을 가르킴
- 리프 블록(LEAF BLOCK) : 인덱스 키 값 + ROWID 저장, <실제 Key값, ROWID>로 구성, 해당 에
- SELECT, DELETE, INSERT 등의 작업에 효율적임
- 분포도가 낮은 컬럼에 불리, OR연산자에 대해 테이블 전체를 FULL SCAN하는 것은 위험
- 테이블의 어느 데이터에 접근하더라도 동일한 성능 보장
- 더블 링크드 리스트 - 리프 블록간 양방향 통신을 의미. 리프 블록의 한 인덱스 값에서 범위(RANGE) 스캔을 빠르게 할 수 있게 해줌
- EX) SELECT ENAME, ADDRESS FROM EMP WHERE EMPNO='03489';

① EMPNO인덱스의 루트 블록 확인. 루트 블록의 Separator Key를 확인해 EMPNO의 값이 03400을 기준으로 더 큰값이면 우측으로, 더 작은 값이면 좌측으로 분기
② 루트 블록의 Separator Key를 통해 03489는 03400보다 크기 때문에 우측 브랜치 블록으로 이동
③ 브랜치 블록을 스캔해 블록 Separator Key를 확인한 결과 <03450,DBA>임. 03450보다 크면 값이 우측으로 작으면 좌측으로 분기. 03489는 03450보다 크므로 우측 아래로 이동
④ 브랜치 블록에서 리프 블록으로 이동하게 되면 해당 블록을 스캔해 <03489,ROWID> 라는 인덱스값 확인
⑤ 해당 인덱스 값의 ROWID를 통해 실제 테이블 액세스
- 이런 방식으로 데이터를 액세스 하기 때문에 어떤 EMPNO를 조회하더라도 루트블록, 브랜치 블록, 리프 블록을 하나씩만 액세스하게됨
1-1. B-TREE 인덱스 변경
- 테이블의 데이터가 수정되면 해당 테이블의 B-TREE 인덱스에서도 INSERT, UDPATE, DELETE 등이 수행되고 이는 성능
저하의 원인이 됨
< Insert Operation >
- 인덱스 엔트리 저장
- 테이블에 데이터가 추가되면 해당 테이블에 존재하는 인덱스에도 추가된 데이터의 인덱스 엔트리가 추가됨
- 테이블에 추가되는 데이터의 인덱스 키 값의 저장 위치를 찾기 위해 인덱스 리프 블록을 확인해 찾고 인덱스 블록의 여유공간에 해당 인덱스 엔트리 추가
- 해당 인덱스 블록에 여유 공간이 없을 경우 해당 블록은 2개의 인덱스 리프 블록으로 분기돼 인덱스 키들은 다시 정렬되고 분기된 2개의 인덱스 리프 블록을 통해 추가
- 이 때 리프블록들을 연결하고 있는 브랜치 블록과 루트 블록의 정보가 갱신될 수 있음
< Delete Operation >
- 기존 인덱스 엔트리 링크 삭제 + 인덱스 엔트리 저장
- Insert Operation과 정반대의 작업 수행
- 데이터가 삭제되면 해당 인덱스 엔트리의 연결이 끊어지고 그로 인해 루트 블록으로부터 해당 인덱스 엔트리를 인식하지 못하게 함
- 삭제된 인덱스 엔트리 공간은 추가를 위해 공간 해제를 수행하게 되며, 리프 블록에 하나의 인덱스 엔트리라도 남게되면 인덱스 리프 블록은 유지됨
- 많은 인덱스 엔트리가 삭제되면 삭제된 공간이 반납되지만 해당 리프블록의 전체 데이터가 삭제되지 않는 한 해당 리프블록은 반납되지 않음
- 그러므로 해당 리프블록에 새로운 인덱스 엔트리가 추가로 저장되지 않는다면 공간이 낭비됨
< Update Operation >
- 기존 인덱스 엔트리 링크 삭제 + 인덱스 엔트리 저장
- 삭제와 추가 작업이 동시에 수행되는 작업
- 테이블에 데이터가 순차적으로 증가해 추가되는 경우 인덱스의 우측으로 인덱스 엔트리가 집중되 B-TREE의 가장 중요한 특징인 균형이 무너지게 됨
- 또한 좌측 리프 블록으로 인덱스 엔트리가 추가되지 않기 때문에 좌측 리프 블록은 블록 사용률이 낮아짐
- 삭제가 많거나 인덱스 키가 순차적으로 증가하며 추가되는 테이블은 주기적인 인덱스 재구성을 통해 인덱스 균형 유지 필요
1-2. B-TREE 인덱스 고려사항
- 인덱스가 적용된 db에서 필요한 값을 찾을 때에는 가장 먼저 테이블을 조회하게 되는데 이과정에서 발생하는 I/O가랜덤 액세스이기 때문에 B-TREE 인덱스를 사용할 때에는 랜덤 액세스의 양을 특히 신경써야 함
- 만약 랜덤 액세스의 양이 지나치게 많으면 B-TREE인덱스를 사용하지 않는 게 좋음
- AND조건은 처리 범위를 감소시키고 OR조건은 처리 범위를 증가시킴. B-TREE인덱스는 처리 범위를 최소화하여 랜덤 액세스를 감소시키는 것이 중요
*B-TREE 인덱스 내용 출처: http://www.gurubee.net/lecture/2935
2. 비트맵 인덱스
- B-TREE인덱스와 달리 비트맵, 즉 0 또는 1로 인덱스를 관리
- 비트를 이용하여 컬럼값을 저장하고, ROWID를 자동으로 생성
- 분포도가 낮은 컬럼에 적용할 때 유용(컬럼이 갖는 데이터가 몇개 안될 때 ex)성별, 결혼여부 등)
- 비트를 직접 관리하므로 저장공간이 크게 감소하고 비트 연산을 수행할 수 있음

- 비트맵 인덱스는 인덱스 키값 + 시작 ROWID + 끝 ROWID + 비트맵 엔트리로 구성되어 있음
- 시작 ROWID와 끝 ROWID의 Range 사이에 있는 모든 row수만큼 비트맵이 표현되어야 하지만, 오라클에서는 내부적인 압축 알고리즘을 사용하여 비트맵을 생성하기 때문에 모두 표현되지 않는 경우도 있음
- 비트맵도 B-TREE처럼 조직되어 있지만, 리프노드는 ROWID값들 대신 각 키값에 대한 비트맵 저장
- OR연산자를 포함하는 여러 개의 where 조건을 자주 사용할 때 유리
- INSERT, UPDATE, DELET와 같은 쿼리에서는 무의미
- 비트맵 인덱스 생성문법
-> CREATE BITMAP INDEX 인덱스명 ON 테이블명 (컬럼)
[TABLESPACE 테이블스페이스명]
...
3. REVERSE KEY 인덱스
- B-TREE 인덱스와 거의 같지만 인덱스 키 값은 반대로 구성해 B-TREE 인덱스 생성
- 구조는 B-TREE인덱스와 같고 단지 저장되는 데이터만 역으로 리프블록에 저장
- 인덱스 범위 스캔 불가
- 우측 리프블록 경합 방지 가능
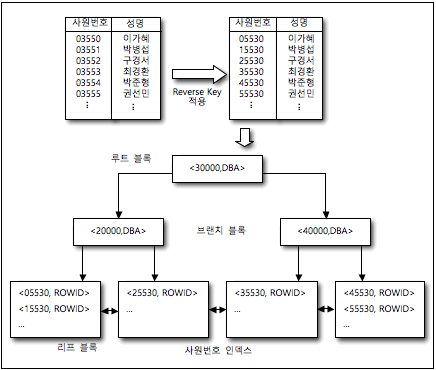
- 사원번호가 03550인 사람을 Reverse Key를 적용하여 05530으로
- 일반적인 B-TREE인덱스는 우측 리프블록으로 모든 데이터가 저장되지만 Reverse Key인덱스는 인덱스 키 값이 순차적으로 증가하더라도 우측 리프블록에만 추가가 발생하지 않고 모든 인덱스 블록으로 추가되게 됨
- Reverse Key 인덱스 생성
-> CREATE INDEX 인덱스명 ON 테이블명(컬럼명) REVERSE;
- B-TREE인덱스에서 Reverse Key인덱스로 변경
-> ALTR INDEX 인덱스명 REBUILD REVERSE | NOREVERSE;
* 리버스키인덱스 내용 출처 : http://www.gurubee.net/lecture/2959
4. 함수 기반 인덱스
- 테이블의 컬럼들을 가공한 값으로 인덱스를 생성한 것
인덱스 스캔 방식의 종류
1. INDEX RANGE SCAN
- 가장 기본적인 방식의 인덱스 스캔
2. INDEX FULL SCAN
- 수직적 탐색없이 인덱스 리프블록을 처음부터 끝까지 탐색하는 것
- 최적의 인덱스가 없을 때 사용하는 차선책
- 인덱스 선두컬럼이 조건절에 없으면 옵티마이저는 우선적으로 TABLE FULL SCAN을 고려하지만 대용량 테이블에서의 TABLE FULL SCAN이 부담된다면 INDEX FULL SCAN을 고려
3. INDEX UNIQUE SCAN
- 수직적 탐색으로만 데이터를 찾는 방식으로 UNIQUE INDEX를 통해 '='조건으로 검색하는 경우에 작동
- UNIQUE INDEX라도 범위조건일 경우(BETWEEN, LIKE등)는 INDEX RANGE SCAN이 됨
- UNIQUE 결합 인덱스에 대한 일부 컬럼만 검색이 될 때도 INDEX RANGE SACN이 이루어짐
4. INDEX SKIP SCAN
- 조건절에서 INDEX 선두컬럼이 빠진 경우 인덱스 선두컬럼의 DISTINCT VALUE 개수가 적고 후행 컬럼의 DISTINCT VALUE 개수가 많을 때 유용
- INDEX SKIP SCAN은 첫번째 리프블록과 마지막 리프블록을 항상 방문
- INDEX 컬럼중 중간이 빠져도 INDEX SKIP SCAN 가능
- 선두컬럼이 부등호, BETWEEN, LIKE와 같은 범위검색 조건일 때도 INDEX SKIP SCAN 사용 가능
- 선두컬럼이 범위검색이어서 나머지 검색조건을 만족하는 데이터들이 서로 멀리 떨어져 있을 때가 유용
5. INDEX FAST FULL SCAN
- 인덱스 트리구조를 무시하고 인덱스 세그먼트 전체를 multiblock read 방식으로 스캔하기 때문에 INDEX FULL SCAN보다 속도가 빠름
- 인덱스 리프노드가 갖는 구조를 이용하지 않기 때문에 얻어진 결과 집합이 인덱스 키 순으로 정렬되지는 않음
- 버퍼캐시 히트율이 낮아 디스크 I/O가 많이 발생할 때 유리
6. INDEX RANGE SCAN DESCENDING
- INDEX RANGE SCAN 과 동일한 방식이나 인덱스 뒤에서부터 앞으로 탐색하기 때문에 내림차순 결과집합 얻음
'Oracle' 카테고리의 다른 글
| [Oracle]ORA-01502: index or partition of such index is in usable state problem 에러 원인/해결 (1) | 2025.08.28 |
|---|---|
| [Oracle] DB BLOCK SIZE (0) | 2021.10.28 |
| SQL문 실행원리 (0) | 2021.10.05 |
| [ORACLE] 백업및 복구(4)_IMP (0) | 2021.04.07 |
| [ORACLE] 백업및 복구(3)_EXP (0) | 2021.04.07 |

댓글